
זיהוי סיבוכים הקשורים למחלת הסוכרת באמצעות ניתוח נתוני עתק מתוך הטקסט החופשי ברשומות רפואיות אלקטרוניות בשפה בעברית
2בית הספר לבריאות הציבור, אוניברסיטת תל אביב, ישראל
3תמנ"ע- תשתיות מחקר נתוני עתק, משרד הבריאות, ירושלים, ישראל
4מכון מחקר, לאומית שירותי בריאות, ישראל
Background And Rationale: Studies have demonstrated 50% to 80% of all health data do not receive a diagnosis by International Classification of Diseases (ICD) codes and mostly recorded as an unstructured free text narrative data without any evaluation. Leumit Health Services (LHS) in collaboration with Israeli Ministry of Health (MoH) conducted a study using the Electronic Medical Records (EMR) to extract meaningful information of diabetic patients.
Objectives: To develop and validate natural language processing (NLP) algorithms in order to identify diabetes-related complications in free text medical records, among members of LHS.
Methods: The study data included 2.3 million records of a total of 41,469 patients with diabetes aged 35 or older between the years 2012-2017. The diabetes-related complications included cardiovascular disease, diabetic neuropathy, nephropathy, retinopathy, diabetic foot, dementia, mood disorders and hypoglycemia. Vocabulary list of terms was determined by an adjudication committee composed of two physicians, one of which are experienced board certified diabetes specialist. Two independent registered nurses reviewed the free text medical records. We performed both rule-based and machine learning techniques for NLP algorithm development. Precision, recall, and F-measure were calculated to compare the performance of NLP algorithm to reviewer`s comments and the ICD codes versus the reviewers for each complication.
Results: The NLP algorithm versus the reviewers (gold standard-GS) achieved overall good performance with an average F-Score of 86% .This was better than the ICD codes which achieved average F-score of only ~ 51% .
Table: NLP performance versus GS and ICD codes versus GS in %.
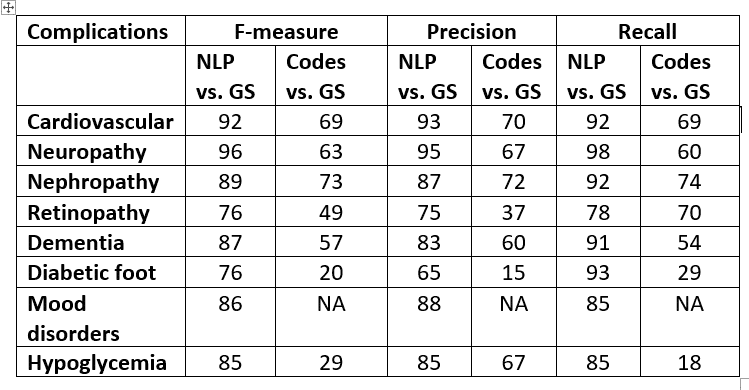
Conclusions: NLP algorithms and machine learning processes may enable more accurate identification of diabetes complications in electronic medical record data.